Using NLP to Leverage Unstructured Data

Image Source: metamorworks/Stock.adobe.com
By Becks Simpson for Mouser Electronics
Published May 6, 2022
While most companies will be familiar with their own structured data and might be aware of artificial intelligence (AI)–based analytics that can help use them, many are at a loss when it comes to unstructured data. These data can assume many forms such as reports, user comments, and support ticket write-ups, and businesses often have more of them than they expect. These data contain impressive insights that can help improve customer experience, workflow effectiveness, and productivity but because they are difficult to process and use, they tend to remain locked away.
Furthermore, without the right expertise, it can be difficult to leverage the modern deep learning–based natural language processing (NLP) methods required to make sense of this kind of data. To improve this situation and help companies unlock value from their unstructured data, the low-code and no-code NLP revolution has begun.
The Rise of Unstructured Data
Companies are producing data at a rapidly increasing rate from a variety of sources like online product reviews, customer comments on social media, internal communications, financial documents, sales databases, quarterly reports, and more. The overwhelming majority of these data tend to be unstructured and unaggregated—because they were collected before machine learning (ML) and other insight-generating technologies were available or without company knowledge on best data practices, and because many sources are naturally unstructured like text.
In fact, IDC estimates that by the year 2025, 80% of the world’s digital data will be unstructured. If companies are able to make sense of these inputs and put their data to good use, they can achieve a wide variety of exciting outcomes.
For example, a business that can distill all its customer reviews into summaries of the most common issues people face without having to read each one will benefit by directly improving its product or service offering at a much faster rate. Organizations that can leverage their internal support tickets to learn to triage incoming requests automatically based on predicted urgency can benefit from faster responses to critical issues and improved productivity overall.
Despite the fact that only 18% of companies are using their unstructured data successfully (Deloitte), across essentially every industry, from finance and product development to shipping and law, increasing the usability of these data by just 10% stands to create projected economic gains of $2 billion in improved productivity (University of Texas).
Challenges of Using Unstructured Data
So few companies actually manage to leverage their unstructured data for several reasons. All AI—from simple ML algorithms based on traditional statistical methods to more complicated deep learning–based approaches—require data that are structured and standardized, but most of the data produced via these various streams will be in free text format.
This means that additional processing is required in order to make them usable for many ML purposes—data scientists could spend 80–90% of their time just cleaning the data to make them ready for modeling. Text, in particular, comes with a variety of challenges including nonstandard language usage, spelling errors, multilingual inputs, domain-specific vocabulary, ambiguous meaning, and overly short or long text, which make some traditional modeling techniques difficult.
Since “garbage in equals garbage out” when it comes to ML and AI, all of these anomalies that might affect insight quality must be treated beforehand. Furthermore, the sources themselves tend to be disparate and require integration efforts to extract the data for processing and modeling.
For example, customer interactions with the company that could be used to understand churn or to improve product processes could come from social media, various review sites, and support tickets from whichever customer relationship management software the company is using, none of which are typically held in the same platform.
In addition to the challenges with the data themselves, fierce competition exists for the talent required to actually do the data wrangling and modeling to drive gains. Even though many small- and medium-sized enterprises know that valuable and actionable information could be hidden in the data they’ve collected, they frequently lack the expertise required to make use of what they have.
Although different ML and AI software solutions are available, they require technical expertise to operate, particularly in the case of application programming interfaces (APIs) or software development kits (SDKs) from giants like Google or Amazon. However, many smaller organizations don’t even have dedicated software or IT teams that could learn to cross-specialize and use available open source AI software to streamline processes and derive insights from internal data.
Depending on the size of the company, hiring a team of data engineering and ML experts to do the work can be prohibitively expensive. Even if the cost savings or profit improvements are significant, if the company is not large enough, those gains might not be enough to justify hiring talent at a premium. Larger companies that are looking to hire a data science and ML team are often met with increasingly tough competition and a pronounced sparsity of candidates.
Therefore, a distinct need exists for solutions that bridge the gap between data and AI experts and those with business know-how and understanding—the rise of low-code and no-code AI solutions incorporating NLP has begun across a range of industries and specific everyday business use cases.
How Can NLP Help?
NLP algorithms support most of the AI solutions made to help companies wrangle their unstructured text data into something meaningful and actionable (Figure 1). These can range from simpler, more traditional statistical models that do pattern matching and identify keywords based on their relative frequency compared to other words to newer, more complex deep learning–based methods.
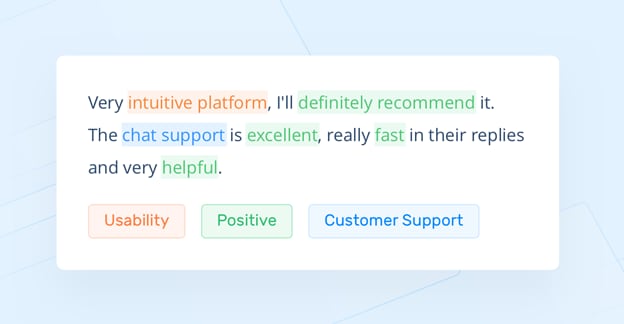
Figure 1: NLP in action to highlight important aspects of a customer review such as sentiment and usability factors (Source: MonkeyLearn)
In particular, the newer NLP models are particularly good at leveraging neural network–based architectures to accomplish more sophisticated tasks that were previously out of reach for language-related automation. Recent advances have made it possible to automatically summarize large blocks of text such as reports, produce more nuanced sentiment analysis, and perform question-answering tasks with alarming accuracy from disparate data sources.
Computer vision models trained on millions of data points have helped companies, researchers, and anyone in between avoid having to stockpile massive amounts of data to train with; the same is now true of NLP models. Some of these modern powerhouse NLP algorithms, pre-trained on millions of examples of natural language for various tasks, can be used as part of various SDKs, APIs, and no-code tools as well as through several open-source software packages.
Importantly, because the deep learning–based models are able to learn without significant feature engineering and data pre-processing, these NLP-derived tools and solutions can be used with little to no data cleaning.
Low-code Solutions: APIs and SDKs
Low-code AI solutions are typically defined as those requiring a minimal amount of technical expertise to operate—specifically knowledge and experience in coding and training ML models. Because some element of coding know-how is still required, these types of solutions are best suited to businesses that already have some in-house developers who can build out the workflows needed for data processing and modeling.
However, as the models themselves are wrapped in easy-to-use code or are callable via APIs, the learning curve is a lot shorter than if the tech team had to learn all of the algorithm writing, training, and deployment from scratch.
Some key players in this field include Google, Amazon, Microsoft, and other similar organizations that provide both APIs and SDKs for developer teams inside other companies to start to use their NLP capabilities to analyze text, identify important terms, and extract key phrases to derive insights from unstructured text data.
Typically, a company wishing to use these low-code NLP solutions on its own data will have some kind of access key for using the APIs available or will use the SDKs, which often call the APIs under the hood, and then will test the functionality of the pre-trained models to determine whether they meet the business’ needs. For example, a company wanting to know the most common themes in complaints can run the data it has through a named entity recognition model to find highlights.
Once the model has been selected, it might be possible to fine-tune on the company’s own data, but more than likely this won’t be necessary; a bit of data wrangling will ensure that the sources of data can connect and feed into where the model will be deployed, usually in the cloud.
Some of the low-code solutions go a step further and border on no-code solutions by allowing users to stream data to a specific data lake, extract certain information, and deploy the NLP models and workflows they want with single-click actions through the chosen solution’s online interface or by stringing together several managed services. For those companies that don’t have the luxury of a tech team ready to engage ML for text data challenges, some offerings have gone even further to completely remove the need to write any lines of code (Figure 2).

Figure 2: Comparing the two, low-code solutions make NLP models easier and faster to use in software workflows while no-code leverages a user interface to build everything. (Source: Dataquest)
No-code Solutions: GUIs
No-code platforms that eliminate the need for technical expertise and expensive and scarce talent, and allow nontechnical people to leverage powerful technology, have been around for a while. Original examples emerged to help companies do things like create and launch websites or build mobile apps using just a graphical user interface (GUI). The ease of use, affordability, and impressive functionality offered by many of the available options meant that having a full-fledged tech team was no longer a hard requirement for many small- to medium-size enterprises (and some large ones, depending on the complexity they were trying to achieve).
Just as AI and data science flourished, the same trend is happening again as no-code solutions democratize AI for everyone. Increasingly, these hyper user-friendly AI platforms can be used for data analysis, modeling, and insight generation. In particular, no-code offerings allow users to interact with their data through interfaces such as drag-and-drop GUIs or Google-style search bars that turn their human queries into machine understandable ones.
Companies like MonkeyLearn, Accern, DataRobot, and ObviouslyAI are making tools so that even non-tech savvy people can use these platforms to upload or click to connect data sources and use graphical elements to determine what they want to happen to the data, how they should be cleaned, and which analyses should appear in the dashboards by leveraging NLP under the hood but exposed through user-friendly interfaces. Others like SparkBeyond, Rogo, Tableau, and Qlik take this a step further and use NLP not only to drive insight discovery and data wrangling but also to understand human commands, as they directly query their data as though asking questions of a data scientist.
Conclusion
As the amount of unstructured text-based data being produced increases and the access to expertise that can unlock insights from those data becomes more scarce, low-code and no-code solutions that leverage NLP are on the rise. These are powerful options for companies seeking to leverage their internal or external data to gain a competitive edge and improve their processes without the burden of trying to build or hire teams to do the work.
AI-based tools can help businesses of all stages start to automatically process, clean, and analyze the unstructured data they have available across a variety of sources. Low-code style APIs and SDKs can help companies with internal software teams use NLP-based models to bring structure to messy text inputs without huge ML and data science teams. No-code platforms, on the other hand, often eliminate the need for tech teams entirely and put the control over analysis and insights in the hands of business experts instead.
In both cases, organizations can finally put their unstructured, text-based data to good use.